
Dienstleistungen der SHI GmbH für Apache NiFi
Service Level Agreements (SLA)
– Garantierte Reaktions- und Lösungszeiten
– Proaktive Überwachung und frühzeitige Fehlererkennung
– Planbare Betriebssicherheit für unternehmenskritische Datenflüsse
Betrieb
– Einrichtung, Konfiguration und Clusterbetrieb von Apache NiFi
– Kontinuierliche Wartung, Performance-Optimierung und Monitoring
– Integration in bestehende IT-Landschaften und Dateninfrastrukturen
Schulungen
– Praxisorientierte Workshops für Administratoren, Entwickler und Datenarchitekten
– Individuell zugeschnittene Trainings – vom NiFi-Einstieg bis zu fortgeschrittenen Datenfluss-Konzepten
– Schulungsunterlagen und Best Practices aus realen Projekten
Support
– Technische Unterstützung bei Fehleranalysen und Optimierungen
– Unterstützung bei der Entwicklung komplexer Datenflüsse
– Schnelle Hilfe bei akuten Betriebsstörungen
Apache NiFi ist die ideale Plattform, um Datenintegration, -transport und -transformation in modernen IT-Landschaften effizient umzusetzen. Mit der Expertise und den Services der SHI GmbH erhalten Unternehmen nicht nur eine funktionsfähige Lösung, sondern auch den sicheren, zuverlässigen und langfristig betreuten Betrieb ihrer NiFi-Umgebungen – inklusive garantierter Verfügbarkeit, fundiertem Know-how und schneller Reaktionszeiten.
Seit über 30 Jahren ist die SHI GmbH mit Sitz in Augsburg ein etabliertes IT-Beratungs- und Softwarehaus, das passgenaue Lösungen für unterschiedlichste Branchen entwickelt. Als langjähriger Partner führender Technologieanbieter wie Cloudera, Elastic, Lucidworks, Apache Solr und OpenSearch bieten wir umfassende Expertise in der Implementierung innovativer und skalierbarer Such- und Analyseplattformen sowie effizienter Datenverarbeitungslösungen.
Unser Leistungsspektrum reicht von der strategischen Beratung über Migration und Integration bis zur individuellen Anpassung und kontinuierlichen Optimierung. Im Bereich der Individualentwicklung realisieren wir flexible Web-Applikationen, Schnittstellen und E-Commerce-Lösungen mit Fokus auf Langlebigkeit. Für Fachverlage haben wir die modulare Publikationsplattform InfoPilot entwickelt, die auf Open-Source-Basis eine effiziente Online-Vermarktung von Fachinhalten ermöglicht. SHI steht für ganzheitliche Betreuung, langfristige Partnerschaften und Wissensaustausch durch Workshops und Schulungen. Mit unserem engagierten Team in Augsburg sind wir Ihr zuverlässiger Partner für die digitale Transformation.
Adresse: SHI GmbH, Konrad-Adenauer-Allee 15, 86150 Augsburg Deutschland
Telefon: +49 821 – 74 82 633 0
E-Mail: info@shi-gmbh.com
Websiten: https://www.shi-gmbh.com, https://shi-softwareentwicklung.de, https://infopilot.de
SHI GmbH
Konrad-Adenauer-Allee 15
86150 Augsburg
Telefon: +49 (821) 7482633-0
https://www.shi-gmbh.com
Head of Sales
E-Mail: michael.anger@shi-gmbh.com
![]()

Die Entwicklung individueller Schnittstellenlösungen für durchgängige digitale Prozesse
Die Spezialisten von SHI analysieren bestehende Systemlandschaften und entwickeln passgenaue API- oder Dateischnittstellen, die ERP-, CRM-, Shop- oder Drittsysteme sicher und performant verbinden. Zum Einsatz kommen moderne Technologien wie REST, SOAP, XML, JSON oder OData – je nach Anforderungen, Datenvolumen und Sicherheitsanforderung.
„Wir ermöglichen es unseren Kunden, dass ihre Systeme untereinander Daten austauschen, als würden sie aus einem Guss stammen – ohne ständiges manuelles Eingreifen“, so ein Sprecher von SHI. Dabei stehen Stabilität, Zukunftsfähigkeit und Wartbarkeit im Vordergrund. Auch Schnittstellen zu Fremdsystemen wie SAP, Microsoft, DATEV oder Versanddienstleistern lassen sich flexibel anbinden.
Besonders im Fokus stehen dabei die Automatisierung wiederkehrender Aufgaben, die Minimierung von Übertragungsfehlern und die Reduktion von Bearbeitungszeiten. SHI übernimmt die Planung, Entwicklung, Dokumentation und langfristige Wartung aller Schnittstellenlösungen – auch bei komplexen oder heterogenen IT-Umgebungen.
Seit über 30 Jahren ist die SHI GmbH mit Sitz in Augsburg ein etabliertes IT-Beratungs- und Softwarehaus, das passgenaue Lösungen für unterschiedlichste Branchen entwickelt. Als langjähriger Partner führender Technologieanbieter wie Cloudera, Elastic, Lucidworks, Apache Solr und OpenSearch bieten wir umfassende Expertise in der Implementierung innovativer und skalierbarer Such- und Analyseplattformen sowie effizienter Datenverarbeitungslösungen.
Unser Leistungsspektrum reicht von der strategischen Beratung über Migration und Integration bis zur individuellen Anpassung und kontinuierlichen Optimierung. Im Bereich der Individualentwicklung realisieren wir flexible Web-Applikationen, Schnittstellen und E-Commerce-Lösungen mit Fokus auf Langlebigkeit. Für Fachverlage haben wir die modulare Publikationsplattform InfoPilot entwickelt, die auf Open-Source-Basis eine effiziente Online-Vermarktung von Fachinhalten ermöglicht. SHI steht für ganzheitliche Betreuung, langfristige Partnerschaften und Wissensaustausch durch Workshops und Schulungen. Mit unserem engagierten Team in Augsburg sind wir Ihr zuverlässiger Partner für die digitale Transformation.
Adresse: SHI GmbH, Konrad-Adenauer-Allee 15, 86150 Augsburg Deutschland
Telefon: +49 821 – 74 82 633 0
E-Mail: info@shi-gmbh.com
Websiten: https://www.shi-gmbh.com, https://shi-softwareentwicklung.de, https://infopilot.de
SHI GmbH
Konrad-Adenauer-Allee 15
86150 Augsburg
Telefon: +49 (821) 7482633-0
https://www.shi-gmbh.com
Head of Sales
E-Mail: michael.anger@shi-gmbh.com
![]()

Big Data effizient nutzen: Maßgeschneiderte Analyselösungen für bessere Entscheidungen
Im Mittelpunkt steht dabei kein Standardprodukt, sondern eine exakt auf den Bedarf zugeschnittene Lösung. Die Analyseplattformen von SHI kombinieren verschiedene Datenquellen – z. B. aus ERP-Systemen, Sensoren, IoT-Geräten oder Webanwendungen – und führen sie in performanten Dashboards oder Prognosemodellen zusammen. Moderne Tools wie Power BI, Python, Elastic Stack oder KI-Modelle kommen dabei je nach Zielsetzung flexibel zum Einsatz.
Typische Anwendungsfelder sind Produktionskennzahlen, Anomalie-Erkennung, Logistikoptimierung, Kundenverhalten oder automatisierte Reportings.
Durch die Visualisierung relevanter Daten in verständlicher Form gewinnen Unternehmen nicht nur Überblick, sondern auch Handlungsspielräume.
Seit über 30 Jahren ist die SHI GmbH mit Sitz in Augsburg ein etabliertes IT-Beratungs- und Softwarehaus, das passgenaue Lösungen für unterschiedlichste Branchen entwickelt. Als langjähriger Partner führender Technologieanbieter wie Cloudera, Elastic, Lucidworks, Apache Solr und OpenSearch bieten wir umfassende Expertise in der Implementierung innovativer und skalierbarer Such- und Analyseplattformen sowie effizienter Datenverarbeitungslösungen.
Unser Leistungsspektrum reicht von der strategischen Beratung über Migration und Integration bis zur individuellen Anpassung und kontinuierlichen Optimierung. Im Bereich der Individualentwicklung realisieren wir flexible Web-Applikationen, Schnittstellen und E-Commerce-Lösungen mit Fokus auf Langlebigkeit. Für Fachverlage haben wir die modulare Publikationsplattform InfoPilot entwickelt, die auf Open-Source-Basis eine effiziente Online-Vermarktung von Fachinhalten ermöglicht. SHI steht für ganzheitliche Betreuung, langfristige Partnerschaften und Wissensaustausch durch Workshops und Schulungen. Mit unserem engagierten Team in Augsburg sind wir Ihr zuverlässiger Partner für die digitale Transformation.
Adresse: SHI GmbH, Konrad-Adenauer-Allee 15, 86150 Augsburg Deutschland
Telefon: +49 821 – 74 82 633 0
E-Mail: info@shi-gmbh.com
Websiten: https://www.shi-gmbh.com, https://shi-softwareentwicklung.de, https://infopilot.de
SHI GmbH
Konrad-Adenauer-Allee 15
86150 Augsburg
Telefon: +49 (821) 7482633-0
https://www.shi-gmbh.com
Head of Sales
E-Mail: michael.anger@shi-gmbh.com
![]()

SHI GmbH aus Augsburg bietet leistungsstarke Web-Apps für digitale Prozesse
Die Web-App-Entwicklung von SHI richtet sich an Unternehmen, die komplexe Geschäftsprozesse über digitale Benutzeroberflächen steuern wollen – ob in der Produktion, im Vertrieb, in der Verwaltung oder im Kundenservice. Dabei kommen moderne Frontend-Technologien wie Angular, React oder Vue.js zum Einsatz, kombiniert mit leistungsfähigen Backends in C#, PHP oder Node.js. Datenbanken wie PostgreSQL, MSSQL oder MongoDB sorgen für flexible, skalierbare Datenspeicherung.
„Unsere Web-Apps laufen geräte- und standortunabhängig im Browser – so sparen Unternehmen Zeit, Kosten und vermeiden Medienbrüche“, erklärt ein Sprecher der SHI GmbH. Besonders gefragt sind auch moderne Kundenportale, Konfiguratoren, Verwaltungsoberflächen oder Logistiklösungen.
SHI begleitet Projekte ganzheitlich: Von der Anforderungsanalyse über UX-Design und Prototyping bis hin zur technischen Umsetzung und Wartung. Die agile Arbeitsweise garantiert schnelle Ergebnisse, transparente Kommunikation und kontinuierliche Weiterentwicklung.
Seit über 30 Jahren ist die SHI GmbH mit Sitz in Augsburg ein etabliertes IT-Beratungs- und Softwarehaus, das passgenaue Lösungen für unterschiedlichste Branchen entwickelt. Als langjähriger Partner führender Technologieanbieter wie Cloudera, Elastic, Lucidworks, Apache Solr und OpenSearch bieten wir umfassende Expertise in der Implementierung innovativer und skalierbarer Such- und Analyseplattformen sowie effizienter Datenverarbeitungslösungen.
Unser Leistungsspektrum reicht von der strategischen Beratung über Migration und Integration bis zur individuellen Anpassung und kontinuierlichen Optimierung. Im Bereich der Individualentwicklung realisieren wir flexible Web-Applikationen, Schnittstellen und E-Commerce-Lösungen mit Fokus auf Langlebigkeit. Für Fachverlage haben wir die modulare Publikationsplattform InfoPilot entwickelt, die auf Open-Source-Basis eine effiziente Online-Vermarktung von Fachinhalten ermöglicht. SHI steht für ganzheitliche Betreuung, langfristige Partnerschaften und Wissensaustausch durch Workshops und Schulungen. Mit unserem engagierten Team in Augsburg sind wir Ihr zuverlässiger Partner für die digitale Transformation.
Adresse: SHI GmbH, Konrad-Adenauer-Allee 15, 86150 Augsburg Deutschland
Telefon: +49 821 – 74 82 633 0
E-Mail: info@shi-gmbh.com
Websiten: https://www.shi-gmbh.com, https://shi-softwareentwicklung.de, https://infopilot.de
SHI GmbH
Konrad-Adenauer-Allee 15
86150 Augsburg
Telefon: +49 (821) 7482633-0
https://www.shi-gmbh.com
Head of Sales
E-Mail: michael.anger@shi-gmbh.com
![]()

InfoPilot von SHI GmbH präsentiert sich in neuem Gewand
Mit der neu gestalteten Webseite stellt SHI alle Funktionen und Vorteile der Fachverlagsplattform InfoPilot in den Mittelpunkt: Von durchgängigem Content Management, der Steuerung und Optimierung von Workflows bis hin zur Sicherung von Datenqualität. Sämtliche Inhalte wurden aktualisiert, überarbeitet und neu geordnet, damit Verlage direkt erkennen, wie sie durch den Einsatz von InfoPilot ihre Effizienz steigern, Prozesse vereinfachen und das Potenzial ihrer Inhalte besser ausschöpfen können.
Die Webseite führt Besucher gezielt durch die wichtigsten Kernbereiche der Plattform: Medienneutrale Datenhaltung, automatisierte Workflows, individuelle Datenmodelle und intelligente Publikationssteuerung. Ergänzt wird dies durch Beispiele aus der Praxis und konkrete Szenarien, wie InfoPilot Verlage bei der Umsetzung moderner Multichannel-Strategien unterstützt – von gedruckten Publikationen über Web und Apps bis hin zu individuellen Kundenportalen.
„Mit der neuen Struktur und den aktualisierten Inhalten wollen wir Verlagen noch deutlicher zeigen, wie InfoPilot ihre tägliche Arbeit unterstützt – vom ersten Manuskript bis zur fertigen Publikation“, so Andreas Steber, Geschäftsführer der SHI GmbH. „Besucher finden jetzt noch schneller, was für sie relevant ist, und erfahren direkt, wie sie mit InfoPilot Zeit sparen und den Wert ihrer Inhalte steigern.“
Die neu gestaltete Webseite ist ab sofort erreichbar unter:
Seit über 30 Jahren ist die SHI GmbH mit Sitz in Augsburg ein etabliertes IT-Beratungs- und Softwarehaus, das passgenaue Lösungen für unterschiedlichste Branchen entwickelt. Als langjähriger Partner führender Technologieanbieter wie Cloudera, Elastic, Lucidworks, Apache Solr und OpenSearch bieten wir umfassende Expertise in der Implementierung innovativer und skalierbarer Such- und Analyseplattformen sowie effizienter Datenverarbeitungslösungen.
Unser Leistungsspektrum reicht von der strategischen Beratung über Migration und Integration bis zur individuellen Anpassung und kontinuierlichen Optimierung. Im Bereich der Individualentwicklung realisieren wir flexible Web-Applikationen, Schnittstellen und E-Commerce-Lösungen mit Fokus auf Langlebigkeit. Für Fachverlage haben wir die modulare Publikationsplattform InfoPilot entwickelt, die auf Open-Source-Basis eine effiziente Online-Vermarktung von Fachinhalten ermöglicht. SHI steht für ganzheitliche Betreuung, langfristige Partnerschaften und Wissensaustausch durch Workshops und Schulungen. Mit unserem engagierten Team in Augsburg sind wir Ihr zuverlässiger Partner für die digitale Transformation.
Adresse: SHI GmbH, Konrad-Adenauer-Allee 15, 86150 Augsburg Deutschland
Telefon: +49 821 – 74 82 633 0
E-Mail: info@shi-gmbh.com
Websiten: https://www.shi-gmbh.com, https://shi-softwareentwicklung.de, https://infopilot.de
SHI GmbH
Konrad-Adenauer-Allee 15
86150 Augsburg
Telefon: +49 (821) 7482633-0
https://www.shi-gmbh.com
Head of Sales
E-Mail: michael.anger@shi-gmbh.com
![]()
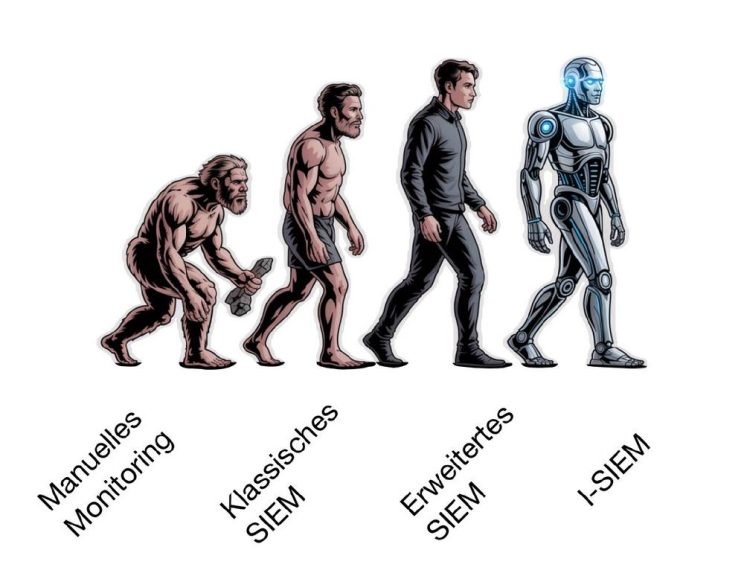
Die Evolution vom Monitoring zum I-SIEM
Der nächste logische Schritt war das klassische SIEM (Security Information and Event Management). Es sammelte Log- und Event-Daten aus verschiedensten Quellen, korrelierte diese anhand definierter Regeln und gab bei Abweichungen automatisch Alarme aus. Ein gewaltiger Fortschritt gegenüber der reinen Handarbeit – doch mit Nachteilen: Die Pflege der Regeln war aufwendig, die Alarmflut oft hoch, und viele Zusammenhänge blieben trotzdem verborgen.
Mit steigender Komplexität der IT-Infrastrukturen entstanden daraufhin erweiterte SIEM-Systeme. Sie boten bessere Dashboards, die Integration zusätzlicher Datenquellen und erste Automatisierungsmöglichkeiten. Analysten konnten Risiken im Kontext sehen, historische Daten schneller auswerten und einfache Workflows automatisieren. Dennoch blieb vieles reaktiv: Das System meldete, wenn etwas passierte – aber nicht, warum es passierte oder wie dringend es wirklich war.
Der nächste Schritt: I-SIEM – Intelligent SIEM
Den entscheidenden Durchbruch bringt heute eine neue Generation von Plattformen, oft als I-SIEM bezeichnet: Intelligent Security Information and Event Management. Diese Systeme ergänzen klassische Log-Sammlung und regelbasierte Korrelation um fortschrittliche KI- und Machine-Learning-Verfahren.
I-SIEM bietet echte Intelligenz:
- Automatische Priorisierung: Die Plattform bewertet Vorfälle anhand von Kontext und Business Impact, sodass Analysten sofort wissen, welche Alarme wirklich kritisch sind.
- Anomalieerkennung: Statt nur bekannte Angriffsmuster zu erkennen, lernt das System selbstständig ungewöhnliches Verhalten zu identifizieren – auch bisher unbekannte Bedrohungen.
- Erklärbarkeit: Mit Natural Language Processing kann das I-SIEM verständlich erläutern, warum ein bestimmtes Ereignis als gefährlich eingestuft wurde.
- Automation: Über integrierte Playbooks lassen sich Reaktionen auf typische Vorfälle automatisieren – von der Quarantäne bis zur Benachrichtigung von Teams.
- Kontinuierliches Lernen: Das System entwickelt sich weiter, lernt aus echten Angriffen, False Positives und Analysten-Feedback.
Warum I-SIEM den Unterschied macht
In einer Zeit, in der Cyberangriffe immer raffinierter werden und Datenvolumen rasant wächst, stoßen rein regelbasierte Systeme an ihre Grenzen. I-SIEM verschiebt die Perspektive: Es arbeitet nicht nur reaktiv (wenn ein Angriff geschieht), sondern proaktiv – erkennt Auffälligkeiten früh, erklärt Zusammenhänge und unterstützt Analysten, Entscheidungen schneller und fundierter zu treffen.
Kurz gesagt: Von reiner Datensammlung zur intelligenten Abwehrzentrale, die mitdenkt, lernt und sich ständig verbessert. Für Unternehmen bedeutet das: Weniger Fehlalarme, schnellere Reaktionszeiten und eine spürbar höhere Sicherheit – auch bei wachsenden Datenmengen und Bedrohungslagen.
Seit über 30 Jahren ist die SHI GmbH mit Sitz in Augsburg ein etabliertes IT-Beratungs- und Softwarehaus, das passgenaue Lösungen für unterschiedlichste Branchen entwickelt. Als langjähriger Partner führender Technologieanbieter wie Cloudera, Elastic, Lucidworks, Apache Solr und OpenSearch bieten wir umfassende Expertise in der Implementierung innovativer und skalierbarer Such- und Analyseplattformen sowie effizienter Datenverarbeitungslösungen.
Unser Leistungsspektrum reicht von der strategischen Beratung über Migration und Integration bis zur individuellen Anpassung und kontinuierlichen Optimierung. Im Bereich der Individualentwicklung realisieren wir flexible Web-Applikationen, Schnittstellen und E-Commerce-Lösungen mit Fokus auf Langlebigkeit. Für Fachverlage haben wir die modulare Publikationsplattform InfoPilot entwickelt, die auf Open-Source-Basis eine effiziente Online-Vermarktung von Fachinhalten ermöglicht. SHI steht für ganzheitliche Betreuung, langfristige Partnerschaften und Wissensaustausch durch Workshops und Schulungen. Mit unserem engagierten Team in Augsburg sind wir Ihr zuverlässiger Partner für die digitale Transformation.
Adresse: SHI GmbH, Konrad-Adenauer-Allee 15, 86150 Augsburg Deutschland
Telefon: +49 821 – 74 82 633 0
E-Mail: info@shi-gmbh.com
Websiten: https://www.shi-gmbh.com, https://shi-softwareentwicklung.de, https://infopilot.de
SHI GmbH
Konrad-Adenauer-Allee 15
86150 Augsburg
Telefon: +49 (821) 7482633-0
https://www.shi-gmbh.com
Head of Sales
E-Mail: michael.anger@shi-gmbh.com
![]()

Elastic SIEM: Kostenvorteil durch innovatives Lizenzmodell
Elastic Security verfolgt einen grundlegend anderen Ansatz – und verschafft Unternehmen damit deutliche Kostenvorteile. Statt Datenvolumen oder Eventzahlen in Rechnung zu stellen, basiert das Lizenzmodell von Elastic Security auf Ressourcenverbrauch, konkret auf genutzter CPU- und RAM-Kapazität. Ob ein Unternehmen täglich 100 GB oder mehrere Terabyte an Logdaten verarbeitet: Entscheidend sind vor allem die tatsächlich genutzten Systemressourcen, nicht die schiere Datenmenge.
Dieses Modell eröffnet zwei entscheidende Vorteile:
- Erstens erlaubt es Sicherheitsteams, uneingeschränkt mehr Datenquellen anzubinden, ohne sofort steigende Lizenzkosten fürchten zu müssen. Gerade in Zeiten immer komplexerer IT-Landschaften – von Cloud-Diensten über IoT bis hin zu OT-Systemen – ist das ein Schlüsselfaktor für eine ganzheitliche Sicherheitsstrategie.
- Zweitens bietet es Unternehmen volle Flexibilität: Wer in modernen Cloud- oder Hybridumgebungen arbeitet, kann die eigene Elastic Security-Instanz bedarfsgerecht skalieren, ohne dabei unvorhersehbare Kostenlawinen auszulösen.
Darüber hinaus fügt sich Elastic Security nahtlos in den Elastic Stack ein, der von Haus aus auf Performance bei großen Datenmengen optimiert ist. Die Integration von generativer KI und LLMs – wie dem Elastic AI Assistant – geschieht ebenfalls ohne separate Lizenzaufschläge, was den Gesamtnutzen zusätzlich erhöht.
Kurz gesagt: Während traditionelle SIEM-Anbieter das Wachstum von Daten mit steigenden Kosten bestrafen, macht Elastic Security mehr Daten nicht teurer – sondern ermöglicht Unternehmen, Datenvolumen in Sicherheit und Wissen umzuwandeln, ohne finanziellen Flaschenhals. Ein Argument, das gerade in Zeiten exponentiell wachsender Cyber-Bedrohungen Gewicht hat.
Seit über 30 Jahren ist die SHI GmbH mit Sitz in Augsburg ein etabliertes IT-Beratungs- und Softwarehaus, das passgenaue Lösungen für unterschiedlichste Branchen entwickelt. Als langjähriger Partner führender Technologieanbieter wie Cloudera, Elastic, Lucidworks, Apache Solr und OpenSearch bieten wir umfassende Expertise in der Implementierung innovativer und skalierbarer Such- und Analyseplattformen sowie effizienter Datenverarbeitungslösungen.
Unser Leistungsspektrum reicht von der strategischen Beratung über Migration und Integration bis zur individuellen Anpassung und kontinuierlichen Optimierung. Im Bereich der Individualentwicklung realisieren wir flexible Web-Applikationen, Schnittstellen und E-Commerce-Lösungen mit Fokus auf Langlebigkeit. Für Fachverlage haben wir die modulare Publikationsplattform InfoPilot entwickelt, die auf Open-Source-Basis eine effiziente Online-Vermarktung von Fachinhalten ermöglicht. SHI steht für ganzheitliche Betreuung, langfristige Partnerschaften und Wissensaustausch durch Workshops und Schulungen. Mit unserem engagierten Team in Augsburg sind wir Ihr zuverlässiger Partner für die digitale Transformation.
Adresse: SHI GmbH, Konrad-Adenauer-Allee 15, 86150 Augsburg Deutschland
Telefon: +49 821 – 74 82 633 0
E-Mail: info@shi-gmbh.com
Websiten: https://www.shi-gmbh.com, https://shi-softwareentwicklung.de, https://infopilot.de
SHI GmbH
Konrad-Adenauer-Allee 15
86150 Augsburg
Telefon: +49 (821) 7482633-0
https://www.shi-gmbh.com
Head of Sales
E-Mail: michael.anger@shi-gmbh.com
![]()

Cloudera im technischen Großhandel
1. Bestandsoptimierung in Echtzeit
Cloudera ermöglicht es, Lagerbestände kontinuierlich mit Echtzeitdaten aus ERP-Systemen, Wareneingängen, Bestellungen, IoT-Sensoren oder Lieferkettenpartnern abzugleichen.So können Algorithmen laufend den optimalen Lagerbestand berechnen:
* Überwachung von Abverkaufsraten, Saisonalitäten und Kundentrends
* Automatisierte Nachbestellungen, sobald definierte Schwellenwerte unterschritten werden
* Frühzeitige Identifikation von Ladenhütern oder Überbeständen zur Vermeidung von Kapitalbindung
2. Lageroptimierung durch integrierte Analysen
Die Cloudera Data Platform (CDP) erlaubt die Zusammenführung und Analyse von Daten aus unterschiedlichen Quellen (z. B. Kommissionierung, Retouren, Lieferzeiten).Damit lassen sich Fragen beantworten wie:
* Welche Artikel müssen näher am Warenausgang gelagert werden?
* Wie können Pickwege verkürzt und Kommissionierfehler reduziert werden?
* Welche Lieferanten verursachen systematisch Verzögerungen?Das Ergebnis: schnellere Abläufe, weniger Suchzeiten, sinkende Kosten.
3. Logistiksteuerung in Echtzeit
Mit Clouderas Streaming- und Machine-Learning-Funktionen (z. B. Apache Kafka, Flink, Spark Streaming) können Logistikprozesse nahezu live überwacht und gesteuert werden:
* Automatische Anpassung der Tourenplanung bei Lieferengpässen oder Staus
* Prognosebasierte Belieferung von Filialen oder Kunden („predictive replenishment“)
* Dynamische Priorisierung eilige Aufträge basierend auf aktuellen Kapazitäten
4. Skalierbarkeit und Flexibilität
Durch die hybride Cloud-Architektur kann Cloudera sowohl On-Premises als auch in der Cloud oder als Kombination betrieben werden – ein wichtiger Vorteil für Handelsunternehmen mit historisch gewachsenen IT-Landschaften.Zudem erlaubt die Plattform es, neue Datenquellen (z. B. Wetterdaten oder Marktdaten) einfach einzubinden, um Prognosemodelle laufend zu verbessern.
Seit über 30 Jahren ist die SHI GmbH mit Sitz in Augsburg ein etabliertes IT-Beratungs- und Softwarehaus, das passgenaue Lösungen für unterschiedlichste Branchen entwickelt. Als langjähriger Partner führender Technologieanbieter wie Cloudera, Elastic, Lucidworks, Apache Solr und OpenSearch bieten wir umfassende Expertise in der Implementierung innovativer und skalierbarer Such- und Analyseplattformen sowie effizienter Datenverarbeitungslösungen.
Unser Leistungsspektrum reicht von der strategischen Beratung über Migration und Integration bis zur individuellen Anpassung und kontinuierlichen Optimierung. Im Bereich der Individualentwicklung realisieren wir flexible Web-Applikationen, Schnittstellen und E-Commerce-Lösungen mit Fokus auf Langlebigkeit. Für Fachverlage haben wir die modulare Publikationsplattform InfoPilot entwickelt, die auf Open-Source-Basis eine effiziente Online-Vermarktung von Fachinhalten ermöglicht. SHI steht für ganzheitliche Betreuung, langfristige Partnerschaften und Wissensaustausch durch Workshops und Schulungen. Mit unserem engagierten Team in Augsburg sind wir Ihr zuverlässiger Partner für die digitale Transformation.
Adresse: SHI GmbH, Konrad-Adenauer-Allee 15, 86150 Augsburg Deutschland
Telefon: +49 821 – 74 82 633 0
E-Mail: info@shi-gmbh.com
Websiten: https://www.shi-gmbh.com, https://shi-softwareentwicklung.de, https://infopilot.de
SHI GmbH
Konrad-Adenauer-Allee 15
86150 Augsburg
Telefon: +49 (821) 7482633-0
https://www.shi-gmbh.com
Head of Sales
E-Mail: michael.anger@shi-gmbh.com
![]()

SHI GmbH – Softwareentwicklung aus Augsburg
Digitale Transformation – einfach gemacht
Web‑Applikationen, entwickelt von SHI, ermöglichen Mitarbeitenden und Unternehmen maximale Flexibilität: Sie sind browserbasiert, plattformunabhängig und barrierefrei zugänglich – im Büro, Homeoffice oder unterwegs mit Smartphone, Tablet oder Laptop. Einfache Bedienung trifft auf modernste Technologien (Java, Angular, React, JSF, PHP, HTML, CSS, JavaScript), um intuitive Nutzererfahrungen zu realisieren.
Der SHI‑Vorteil: Prozess und Leistung aus einer Hand
SHI begleitet Kunden durch fünf präzise abgestimmte Projektphasen:
- Beratung – ganzheitliche Analyse und ehrliche Einschätzung
- Anforderungsanalyse – individuelle Lösungen durch maßgeschneiderte Planung
- Umsetzung – agile Programmierung mit moderner Dokumentation
- Rollout – reibungslose Integration der Software
- Betrieb & Support – Hosting, Wartung und SLA‑Support für nachhaltigen Betrieb
Technischer Fokus: Komplexe Web‑Apps mit Struktur
Ob datenreiche Anwendungen, Schnittstellen oder klassische Unternehmenssoftware – SHI realisiert anspruchsvolle Projekte mit sauberer Softwarearchitektur. Individuelle REST‑Services und Microservice-Ansätze sorgen für optimierte Datenflüsse und hohe Agilität in der Entwicklung wie im Betrieb.
Ihre Vorteile auf einen Blick
- Plattformübergreifende Verfügbarkeit: Web-Apps funktionieren auf jedem Gerät mit Browser
- Effizienzsteigerung durch intuitive UX und intelligente Funktionen
- Langfristige Flexibilität dank zukunftssicherer Architektur und einfacher Wartbarkeit
- Auswahl moderner Frameworks, je nach Projektanforderung – von React über Angular bis Python oder NoSQL
Perspektive: Digitalisierung vor Ort
Als regionales Unternehmen mit über 30 Jahren Erfahrung und mehr als 500 erfolgreichen Projekten, ist SHI der zuverlässige Partner für Unternehmen, die digitale Abläufe modernisieren und nachhaltig optimieren möchten.
Seit über 30 Jahren ist die SHI GmbH mit Sitz in Augsburg ein etabliertes IT-Beratungs- und Softwarehaus, das passgenaue Lösungen für unterschiedlichste Branchen entwickelt. Als langjähriger Partner führender Technologieanbieter wie Cloudera, Elastic, Lucidworks, Apache Solr und OpenSearch bieten wir umfassende Expertise in der Implementierung innovativer und skalierbarer Such- und Analyseplattformen sowie effizienter Datenverarbeitungslösungen.
Unser Leistungsspektrum reicht von der strategischen Beratung über Migration und Integration bis zur individuellen Anpassung und kontinuierlichen Optimierung. Im Bereich der Individualentwicklung realisieren wir flexible Web-Applikationen, Schnittstellen und E-Commerce-Lösungen mit Fokus auf Langlebigkeit. Für Fachverlage haben wir die modulare Publikationsplattform InfoPilot entwickelt, die auf Open-Source-Basis eine effiziente Online-Vermarktung von Fachinhalten ermöglicht. SHI steht für ganzheitliche Betreuung, langfristige Partnerschaften und Wissensaustausch durch Workshops und Schulungen. Mit unserem engagierten Team in Augsburg sind wir Ihr zuverlässiger Partner für die digitale Transformation.
Adresse: SHI GmbH, Konrad-Adenauer-Allee 15, 86150 Augsburg Deutschland
Telefon: +49 821 – 74 82 633 0
E-Mail: info@shi-gmbh.com
Websiten: https://www.shi-gmbh.com, https://shi-softwareentwicklung.de, https://infopilot.de
SHI GmbH
Konrad-Adenauer-Allee 15
86150 Augsburg
Telefon: +49 (821) 7482633-0
https://www.shi-gmbh.com
Head of Sales
E-Mail: michael.anger@shi-gmbh.com
![]()

Wie Pharmaunternehmen mit OpenSearch ihre Daten zurückerobern
OpenSearch ermöglicht es, strukturierte und unstrukturierte Daten in Echtzeit zu indexieren und auszuwerten. Pharmaunternehmen nutzen diese Fähigkeit beispielsweise, um große Textsammlungen aus Forschungsprojekten oder klinischen Studien schnell durchsuchen und miteinander in Beziehung setzen zu können. Dies beschleunigt nicht nur den Wissenstransfer innerhalb von Forschungs- und Entwicklungsteams, sondern hilft auch dabei, regulatorisch relevante Dokumentationen konsistent vorzuhalten und zu durchsuchen. Gerade die Volltextsuche über internationale Studienregister, Patentschriften oder wissenschaftliche Publikationen wird durch OpenSearch erheblich vereinfacht. Auch interne Wissensdatenbanken, SOPs und Schulungsunterlagen können einheitlich durchsuchbar gemacht werden, sodass Mitarbeiter jederzeit auf aktuelle und geprüfte Informationen zugreifen können.
Neben der reinen Suche spielt für Pharmaunternehmen die Fähigkeit zur Datenvisualisierung eine große Rolle. OpenSearch Dashboards, die aus dem Elasticsearch-Ökosystem hervorgegangen sind, erlauben es, komplexe Zusammenhänge interaktiv darzustellen – etwa Trends in klinischen Studien, Produktionschargen oder Qualitätskontrollen. Dies erleichtert nicht nur die Analyse durch Fachabteilungen, sondern unterstützt das Management bei strategischen Entscheidungen auf Basis aktueller Daten. Durch die offene Architektur lassen sich dabei weitere Systeme wie LIMS (Labor-Informations- und Management-System), ERP oder Dokumentenmanagementplattformen integrieren, sodass ein vollständiges Bild der Datenlandschaft entsteht.
Ein weiteres Argument für OpenSearch ist die Kontrolle über die eigene Datenplattform. Anders als bei proprietären Suchlösungen behalten Pharmaunternehmen die volle Hoheit über Code, Datenhaltung und Systemarchitektur. Dies schafft Vertrauen im Hinblick auf Datenschutz und ermöglicht individuelle Anpassungen, zum Beispiel für spezielle regulatorische Anforderungen wie FDA 21 CFR Part 11 oder GxP-Richtlinien. Gleichzeitig können durch den Einsatz von OpenSearch Kosten reduziert werden, da keine Lizenzgebühren für ein geschlossenes Produkt anfallen und der Betrieb on-premises oder in einer eigenen Cloud-Umgebung realisiert werden kann.
Gerade mittelständische Pharmaunternehmen profitieren von der Flexibilität und Offenheit der Lösung. Häufig wird OpenSearch zunächst für ein bestimmtes Projekt oder Anwendungsgebiet eingeführt, etwa zur Vereinheitlichung der Suche über Forschungsdatenbanken. Nach erfolgreichen Pilotphasen wird die Plattform dann schrittweise auf weitere Bereiche ausgedehnt, etwa auf Qualitätsmanagement, Pharmacovigilance oder Lieferkettenmonitoring. Dank der breiten Unterstützung durch die Community und den Open-Source-Charakter können individuelle Erweiterungen oder Integrationen in bestehende IT-Landschaften schnell umgesetzt werden.
Seit über 30 Jahren ist die SHI GmbH mit Sitz in Augsburg ein etabliertes IT-Beratungs- und Softwarehaus, das passgenaue Lösungen für unterschiedlichste Branchen entwickelt. Als langjähriger Partner führender Technologieanbieter wie Cloudera, Elastic, Lucidworks, Apache Solr und OpenSearch bieten wir umfassende Expertise in der Implementierung innovativer und skalierbarer Such- und Analyseplattformen sowie effizienter Datenverarbeitungslösungen.
Unser Leistungsspektrum reicht von der strategischen Beratung über Migration und Integration bis zur individuellen Anpassung und kontinuierlichen Optimierung. Im Bereich der Individualentwicklung realisieren wir flexible Web-Applikationen, Schnittstellen und E-Commerce-Lösungen mit Fokus auf Langlebigkeit. Für Fachverlage haben wir die modulare Publikationsplattform InfoPilot entwickelt, die auf Open-Source-Basis eine effiziente Online-Vermarktung von Fachinhalten ermöglicht. SHI steht für ganzheitliche Betreuung, langfristige Partnerschaften und Wissensaustausch durch Workshops und Schulungen. Mit unserem engagierten Team in Augsburg sind wir Ihr zuverlässiger Partner für die digitale Transformation.
Adresse: SHI GmbH, Konrad-Adenauer-Allee 15, 86150 Augsburg Deutschland
Telefon: +49 821 – 74 82 633 0
E-Mail: info@shi-gmbh.com
Websiten: https://www.shi-gmbh.com, https://shi-softwareentwicklung.de, https://infopilot.de
SHI GmbH
Konrad-Adenauer-Allee 15
86150 Augsburg
Telefon: +49 (821) 7482633-0
https://www.shi-gmbh.com
Head of Sales
E-Mail: michael.anger@shi-gmbh.com
![]()